About my academic research
My post-doc project in Dr. Jonathan Brennan's Computational Neurolinguistics Lab at the University of Michigan involved taking EEG recordings from interlocutors in unscripted conversation to build a neurolinguistic corpus of naturalistic native and second language speech. In a subsequent step, we tested competing models of L1 and L2 grammar processing to see which theories better align with the observed brainwaves. This work was supported by National Science Foundation SPRF Postdoctoral Fellowship award number 2203723.
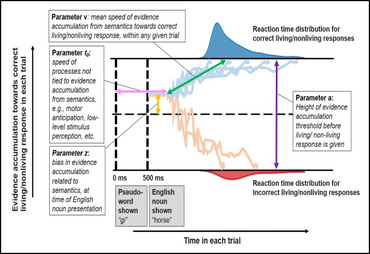
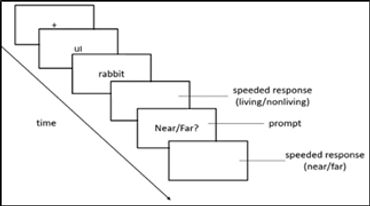
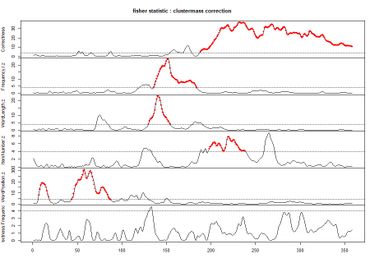
My PhD dissertation at the University of Illinois - Chicago in Dr. Kara Morgan-Short's Cognition of Second Language Acquisition lab used machine learning to pull apart neural indices of conscious vs. subconscious L2 processing. In my experiment, participants were exposed to an artificial language with a hidden grammar pattern. By triangulating language task reaction times, subjective reports, and EEG data, I tested whether focusing on a grammar rule can help or hinder acquisition at a more implicit level. The long game is to find an optimal trade-off between form-vs. meaning-based approaches to language learning, asking questions such as: can L2 learners deliberately change how they allocate attention during real-time L2 processing to improve acquisition? The cherry on top would be to tailor these recommendations according to individuals' particular profiles (which may vary along dimensions of working memory, executive control, sheer tolerance for boredom during repetitive practice, etc.). This was supported by National Science Foundation Dissertation Improvement Grant award number 1941189 as well as a Dingwall Foundation Dissertation Fellowship in the Cognitive, Clinical, and Neural Foundations of Language, an American Philosophical Society John Hope Franklin Dissertation Fellowship, and an Institutes for Citizens & Scholars (formerly Woodrow Wilson National Fellowship Foundation)/Mellon Mays Fellowship Travel and Research Grant.
I also performed research on how grammar learning can be conceived as the gradual acquisition of recurring statistical patterns in L2 input, such that grammatical constructions emerge gradually as the result of processes of abstraction over individual exemplars of a particular form. Language educators could facilitate this process by manipulating factors like token frequency ("How often do you encounter this particular form?"), type frequency ("How many different candidate forms do you see in this particular context?"), and input skewedness ("For this context, to what extent does one or a few forms make up the lion's share of the input?"). Beyond informing psycholinguistic theory, this answers practical praxis questions such as: does encountering a form more frequently necessarily make it easier to recognize and produce? Is it better to teach new grammar by using a wide variety of words in the examples, or by sticking to a few familiar vocabulary items? Should teachers try to emulate the input frequencies encountered “in the real world,” or is it possible to tailor classroom input to facilitate L2 acquisition?
I've also dipped my toes into corpus research with projects like:
- profiling the richness of language learner vocabulary through word frequency analyses of written essays
- analyses of how semantic word properties affect development of Spanish dative constructions across L2 writers at different proficiency levels
- comparisons of heritage vs. native speaker collocations in Spanish dative clitics
Check out some recorded conference presentations below!

Photo Gallery